全体像
まず、機械学習は大きく以下の3つに分類することができます。
- 教師あり学習
- 教師なし学習
- 強化学習
教師あり学習とはその名の通り学習データに対し正解となるデータ(教師データ)を与え、それをもとに学習を行う方法であり、回帰問題や分類問題に用いられています。例えば株の価格予測やトレンド予測などに応用されています。
教師なし学習は教師あり学習とは異なり、教師データを用いない学習方法であり、データの特徴の抽出、表現の変換などに用いられます。クラスタリングや次元圧縮に使用され、例えばクレジットカードの不正検知などに応用されています。
今回のテーマである強化学習は教師あり学習、教師なし学習を合わせた様な性質を持っており、学習データのみを用いると同時に、与えられた報酬を最大化する様ことを目指して学習を行う方法です。
具体的にはまず、ある環境(後述します)内におけるエージェント(後述します)が、現在の状態を観測し、それを元に行動を選択し、その結果として環境からフィードバックとして報酬を受け取ります。次にエージェントは受け取った報酬を元に行動選択の原理を改善します。
強化学習の中でも特に状態の観測や行動の選択において深層学習モデルを使用する深層強化学習は囲碁AIなど様々な場面で利用されています。
環境とエージェントの相互作用について
エージェントとは認知、判断、行動を行う主体であり、環境とはエージェントが制御しようとする対象のことを指しています。
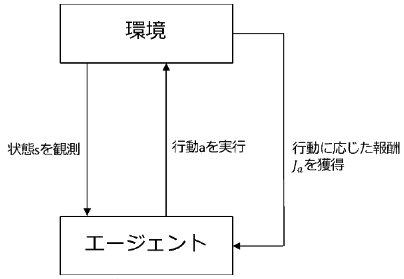
具体的な相互作用については以下のようになります。
- step1状態の観測
エージェントは環境から状態sを観測し、それに基づいて行動aを実行する。
- step2環境からフィードバック
エージェントは行動aの結果として、環境から報酬Jaをフィードバックとして受け取ります。
- step3方策の最適化
エージェントは獲得した報酬Jaを基に方策(行動原理)の最適化を行います。
エージェントは以上のような環境との相互作用を繰り返すことにより最適な方策を学習します。
学習方法
強化学習の学習方法は価値関数ベースの学習方法と、方策関数ベースの学習方法の二つに分類することができます。
価値関数ベース
価値関数ベースの学習方法とは報酬Jaを近似する関数q(s,a)を学習する方法です。
方策については、近似した価値関数を最大化する行動aを最適な方策として設定します。
つまり、価値関数ベースの学習方法の場合エージェントの方策は、以下の式で求めることができます。
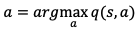
しかし、この学習方法の場合エージェントが取れ方策空間が離散的な場合に限られてしまいます。方策が連続的な場合は次の方策関数ベースの学習方法が望ましいでしょう。
方策関数ベース
方策関数ベースの学習方法とは、行動の選択自体を関数として近似するという方法です。
この場合、エージェントがとる方策はパラメータθの関数として
a=μ(s|θ)
と表すことができます。
今回は決定論的(確率的でない)な方策を想定しています。
エージェントは上記の方策に基づいた報酬Jθによって次の様に方策関数の最適化を実行します。
θ→θ+λ∇θJθ
ここでλは学習率を表しています。
このように方策関数ベースの学習方法の場合、連続的な行動を扱うことができます。
終わりに
今回は強化学習の概要について見てきました。
学習方法についてはプロジェクト等の対象に合わせて価値関数ベースか方策関数ベースか決めるのが良いでしょう。
強化学習をファイナンス、特にポートフォリオ最適化に応用にする方法についての記事も執筆したのでご覧いただけますと幸いです。
ご清覧ありがとうございました。