はじめに
以前、当ブログで強化学習の概要について解説しました。
今回は強化学習を実務、とりわけ資産運用・ポートフォリオ最適化においてどのように取り扱うのか考えてみたいと思います。
ポートフォリオ最適化とは
ポートフォリオ最適化とは与えられたユニバースから資産を選択し、その運用ウェイトを決定することです。
ユニバースとはポートフォリオを運用する際の投資対象の集合体です。ファンドの運用を運用する際はまず運用方針に基づいて一定のユニバースを選定しそこから実際に投資する銘柄を絞り込みます。
ファイナンス・金融工学の分野においてMarkowiz(1952)の平均分散ポートフォリオから端を発し現在までさまざまなポートフォリオ最適化法が提案されています。
しかし、これらは資産リターンの確率分布の仮定など様々な制約に依存しています。特に一般的に資産リターンは非常にノイズが多く、カオスな性質を持つので金融工学的な手法を用いたポートフォリオ最適化法の仮定を満たすのは不可能でないにしても困難が多いと言えます。
しかし、ビックデータやCPU、GPUなどのマシンパワーの上昇も伴い、従来のような強い仮定が必要ない強化学習などのAI・機械学習を用いたポートフォリオ最適化法が注目を集めています。
ポートフォリオ最適化へ応用する際の考え方
それでは実際に強化学習をポートフォリオ最適化に応用する際の考え方について説明していきます。
まずは価値関数ベースか方策関数ベースかを決定する必要があります。
ポートフォリオ最適化において方策が離散的な場合(Buy, Sell, Stay)など限られた行動しかすることができません。
方策が連続的な場合は運用ウェイトを連続する実数として管理することができ、よりきめ細かな運用が可能になるため今回は方策関数ベースの方法を採用することにしました。
方策関数ベースの学習方法につきましては前回の記事をご覧ください。
ではエージェントと環境について見ていきます。
下図はエージェントをポートフォリオ最適化を実行する主体、環境を株式市場(今回は株式市場に限定していますが、その他にも外国為替市場や債券市場なども想定されます)とした場合の相互作用を表しています。
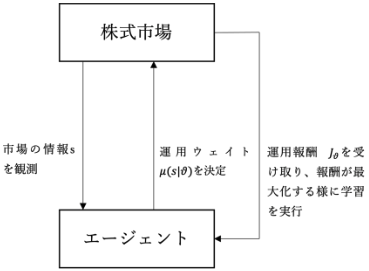
まとめると以下のようになります。
- step1状態の観測
エージェントが株式市場から市場の株価データなどの情報sを観測する。
- step2行動選択
エージェントは自身が管理するパラメータをθとする運用ウェイト決定関数μを基に資産の運用ウェイトμ(s|θ)を決定し、実際に株式市場で運用を行う。
- step3環境からのフィードバック
エージェントは株式市場から資産運用の結果である運用益等の報酬Jθを受け取る。
- step4方策関数の改善
エージェントは報酬Jθが最大化する様に、運用ウェイト決定関数のパラメータを更新する。
上のタイムラインはエージェントと環境の相互作用における1サイクルを表しています。
エージェントはこのサイクルを複数回繰り返すことにより自身の運用ウェイト決定関数の最適化を行います。
終わりに
以上、簡単ではありますが強化学習を資産運用・ポートフォリオ最適化へ応用する際の考え方についてでした。
では実際にどのようなモデルを構築して学習すれば良いのか、先行研究などをまとめた記事も今後投稿しようと思っています。
ご清覧ありがとうございました。

